
2020年写的笔记,仅供存档。
过拟合问题
分类模型的误差大致分为两种:训练误差(Training Error) 和 **泛化误差(Generalization Error)**。训练误差也成 再代入误差(Resubstitution Error) 或 表现误差(Apparent Error),是在训练记录上误分类样本的比例,而泛化误差是模型在位置记录上的期望误差。该方法学习到的模型对未知数据的预测能力,是学习方法本质上重要的性质。现实中采用最多的办法是通过测试泛化误差来评价学习方法的泛化能力。泛化误差界刻画了学习算法的经验风险与期望风险之间偏差和收敛速度。
导致模型过拟合(Overfitting)的潜在因素:
噪声导致的过拟合
缺乏代表性样本导致的过分拟合
多重比较问题(有待解释清楚):主要指的是,当我们存在多个标签值的时候,决策树算法要选择一个最佳属性$x_{\max}$ 来划分数据,然而这多个标签属性随着属性的数量增加,为了判断是否加入到初始决策树中,我们需要判断以下等式: $$ \Delta(T_0,T_{x_{\max}})>\alpha $$ 其中$\alpha$是我们确定的阈值。$k$的数量增加就会导致这个等式成立的可能性进一步加大,这导致了我们可能在不经意间加入了一些欺骗性的结点导致了模型的过分拟合。
泛化误差估计。提供部分估计泛化误差的方法。
使用再代入估计。这种方法就是泛化误差的乐观估计,考虑最低的训练误差,为我们的最终模型。
结合模型复杂度。一般我们考虑奥卡姆剃刀(Occam’s razor)或者节俭原则(principle of parsimony)。也就是尽可能的选择简单的模型。类似于$BIC$和$AIC$那样子,我们同样称这个叫 悲观误差估计:决策树$T$的悲观估计$e_g(T)$可以用下式计算: $$ e_g(T) = \frac{\sum_{i = 1}^k[e(t_i)+\Omega(t_i)]}{\sum_{i = 1}^kn(t_i)} = \frac{e(T)+\Omega(T)}{N_t} $$ 其中,$k$ 是决策树的叶结点数,$e(T)$决策树的总训练误差,$N_t$是训练记录数,$\Omega(t_i)$是每个结点$t_i$对应的惩罚项(类似于$-2\log n$一样。
最小描述长度原则。MDL
先剪枝后剪枝。一个是提前终止,另一个是子树提升或子树替换。
比较两个模型的性能
类似于数理统计中的二项分布检验,检验误差是否显著。$p$就是误差率$n$就是样本数。目的是,为了误差率跨过0%,也就是置信区间要跨过0,即误差率为0。
比较两种分类法的性能
一样的是假设误差来自于正态分布,然后利用$t$检验来检验二者是否相同。
一些其他的决策树
GBDT
Gradient Boosting Decision Tree(GBDT)是梯度提升决策树。GBDT模型所输出的结果是由其包含的若干棵决策树累加而成,每一棵决策树都是对之前决策树组合预测残差的拟合,是对之前模型结果的一种“修正”。梯度提升树既可以用于回归问题(此时被称为CART回归树),也可以被用于解决分类问题(此时被称为分类树)。
博弈树
【Python数据挖掘课程】四.决策树DTC数据分析及鸢尾数据集分析这个附代码,挺给力的。
其他分类技术
基于规则的分类器
P127
最近邻分类器(Nearest Neighbor)
积极学习方法与消极学习方法:
- 积极学习方法(Eager Learner): 决策树和基于规则的分类器。如果训练数据可用,它们就开始学习从输入属性到类标号的映射模型。
- 消极学习方法(Lazy Learner): 例子有 Rote **分类器(Rote Classifier)**。采取与之相反的策略,推迟对训练数据的建模,直到需要分类测试样例时再进行。
算法:检测需要预测点周围最近的k个点,然后考虑最多的类别的点。
贝叶斯分类器
重温贝叶斯定理:balabala
朴素贝叶斯分类器(Naive Bayes classifier)
主要有以下假设,在估计类条件概率的时候假设属性之间条件独立,也就是 $$ P(\textbf X|Y = y) = \prod_{i = 1}^dP(X_i|Y=y) $$ 因此我们可以这样计算后验概率: $$ P(Y|\textbf X) = \frac{P(Y)\cdot\prod_{i = 1}^dP(X_i|Y)}{P(\textbf X)} $$ 由于$P(\textbf X)$(给定了$Y$)都是固定的,因此我们只需要考虑分子。类似于贝叶斯统计中的正比于$\propto$ .
离散情况
如果是离散情况的话,那么条件分布很容易计算,只需要计算他们各自在对应$Y$下的个数再除以总数即可。
连续情况的条件概率
我们有两种方法来估计连续属性的类条件概率。
- 每一个连续属性离散化,然后用相应的离散区间替换连续属性值。
- 利用正态分布。假设连续变量服从某种概率分布,一般取正态分布,然后利用样本均值和样本方差来估计正态分布,也就是$X\sim N(\bar{x},s^2)$。这就是类似于我们在MVA学习的Bayes Classification Rule。
最终我们考虑后验概率最大的为我们的分类类别。
这与我们在MVA学到的类似。回顾MVA,若是两组的情况,则考虑的是, $$ \frac{f_1(\textbf X)}{f_2(\textbf X)}\leq \left(\frac{c(1|2)}{c(2|1)}\right)\left(\frac{p_2}{p_1}\right) $$
条件概率的$\boldsymbol m$估计
如果一个属性的类条件概率等于0,则整个类的后验概率就等于0。因此我们提出了$m$估计(m-estimate)方法来估计条件概率: $$ p(x_i|y_j) = \frac{n_c + mp}{n+m} $$ 其中$n$是类$y_j$中的实例总数,$n_c$是类$y_j$的训练样例中取值$x_i$的样例数,$m$是称为等价样本大小的参数,而$p$是用户指定的参数。
- $p$的取值:$p$可以看作是在类$y_j$的记录中观察属性值$x_i$的先验概率。等价样本大小决定先验概率$p$和观测概率$n_C/n$之间的平衡。
- $m$的取值??
朴素贝叶斯分类器的特征
- 面对孤立的噪声点,朴素贝叶斯分类器仍然是健壮(Robust)的。
- 面对无关属性,也是健壮的。
- 相关属性会降低朴素贝叶斯分类器的性能。条件独立假设不成立。
贝叶斯的误差率
事实上也就是误分的概率。例如在MVA中学习到的ECM(Expected cost of misclassification)。 $$ ECM = c(2|1)P(2|1)p_1 + c(1|2)P(1|2)p_2 $$ $(2|1)$表示实际上是Group 1 但被分到Group2。
在这里我们记贝叶斯误差率为 $$ \mbox{Error} = \int_{R_1}f_2(\textbf X)\mathrm{d}\textbf X + \int_{R_2}f_1(\textbf X)\mathrm{d}\textbf X $$
贝叶斯信念网络
也就是Bayesian Belief Networks(这里我们可以将Belief理解为概率), BNN,简称贝叶斯网络。用图形来表示一组随机变量之间的概率关系。贝叶斯网络有两个主要成分,
- 一个有向无环图(dag),表示变量之间的依赖关系。
- 一个概率表,把各结点和它的直接父结点关联起来。
输入:已知之前条件,发生下一个结点的概率。
输出:给定一个条件,输出某一项的概率。这个概率是可以层层推进计算出来的。
人工神经网络
理解所需的一些知识
Denominator Layout 分母布局
Nominator Layout 分子布局
设$f(\textbf x)$是$\textbf x$的标量函数,正常的梯度: $$ \frac{\partial f(\textbf x)}{\partial \textbf x} = \begin{pmatrix} \frac{\partial f(\textbf x)}{\partial x_1}\\ \frac{\partial f(\textbf x)}{\partial x_2}\\ \vdots\\ \frac{\partial f(\textbf x)}{\partial x_n}\end{pmatrix} $$ 而转置的梯度: $$ \left(\frac{\partial f(\textbf x)}{\partial \textbf x}\right)^T =\frac{\partial f(\textbf x)}{\partial\textbf x^T}=\begin{pmatrix} \frac{\partial f(\textbf x)}{\partial x_1}& \frac{\partial f(\textbf x)}{\partial x_2}& \cdots& \frac{\partial f(\textbf x)}{\partial x_n}\end{pmatrix} $$
感知器Perceptron
简单的单层神经网络——感知器。

给定权重,然后获得一个最终的加权和,然后利用激活函数Activiation function得到最后的结果。
几个教程:
一个前置知识:

求解距离$d$和为什么$w$是法向量还有另外的解法。
$w$是法向量可以用向量积点乘推出来:选取两个在$\textbf w\cdot\textbf x + b = 0$上的点$x_1,x_2$,我们知道$\textbf x_1 – \textbf x_2$一定是在这条直线上的,因此有 $$ \textbf w(\textbf x_1-\textbf x_2) = 0 $$ 所以$\textbf w$与在这条直线上的向量内积为0,因此$\textbf w$一定是该直线的法向量。
距离$d$见底下的推导(SVM的)。
感知器:
感知器是典型的线性分类学习算法。给定$N$个样本的训练集:$(x^{(n)},y^{(n)})^{N}{n=1}$,其中$y^{(n)}\in\lbrace+1,-1\rbrace$,试图找到一组参数$w^*, b^*$,使得每个样本$(x^{(n)},y^{(n)})^{N}{n=1}$,有 $$ y^{(n)}(w^{T}x^{(n)} + b^)>0,\quad\forall n\in[1,N] $$ 其实也就是正确率。其中$\hat{y} = w^{T}x^{(n)} + b^$。因此,只要预测正确,其值就会大于0。
激活函数(Activiation Function)
在这里我们利用的是Sign函数 $$ \mbox{Sign}(x) = \begin{cases} -1, &x0\\ \end{cases} $$ 一般我们舍弃掉$x=0$的部分,也就是只有$x>0, y= 1$和$x\leq0,y=-1$。
目标
最小化loss function, $M$为误分类的样本 $$ \min_{w,b} L(w,b) = -\sum_{x_i\in M} y_i(w\cdot x_i + b) $$ 损失函数的梯度为: $$ \nabla_wL(w,b) = -\sum_{x_i\in M}y_ix_i $$
$$ \nabla_bL(w,b) = -\sum_{x_i\in M}y_i $$
然后选取一个学习步长,也就是学习率$\eta$。
更新方式(学习方式)
梯度的性质
函数$f(x)$在点$x_0$处的负梯度$-\nabla f(x_0)$是$f(x)$在点$x_0$处最快的下降方向。
证明:由泰勒公式知: $$ \begin{eqnarray} f(x_0 + \lambda p) – f(x_0) &=& \left(\nabla f(x_0)\right)^T\cdot\lambda p+o(\|\lambda p\|)\\ &=&\lambda\left(\nabla f(x_0)\right)^T\cdot p +o(\|\lambda p\|) \end{eqnarray} $$ 因此略去高阶无穷小量$o(\|\lambda p\|)$不计,取$p = -\nabla f(x_0)$时,函数$f(x)$下降最快。这里$\lambda$就是步长。
GD(Gradient Descent)
正常的梯度下降方式。以Perceptron为例,我们的梯度可以近似的看作 $$ \begin{eqnarray} \nabla_wL(w,b) &=& -\sum_{x_i\in M}y_ix_i\\ \frac{\partial L(w,b)}{\partial w} &=& -\sum_{x_i\in M}y_ix_i\\ \end{eqnarray} $$ 其实也可以近似看作是($\Delta w_t$很小的时候) $$ \frac{L_{t+1} – L_t}{w_{t+1}-w_t} = -\sum_{x_i\in M}y_ix_i $$ 这其实就是损失函数的在$w_t$的导数。为了获得更小的损失函数值,我们往损失函数减小的方向前进,也就是要使 $$ \begin{eqnarray} L_{t+1} – L_t =-(w_{t+1}-w_t)\cdot\sum_{x_i\in M}y_ix_i&\leq&0\\ (w_{t+1}-w_t)\cdot\sum_{x_i\in M}y_ix_i&\geq&0 \end{eqnarray} $$ 我们不妨顺着切线的方向,以获得下一个使损失函数变小的$w_{t+1}$的值,也就是, $$ w_{t+1} = w_t + \eta\cdot\sum_{x_i\in M}y_ix_i $$ 其中学习率$\eta$为重要的调参参数。
SGD(Stochastic Gradient Descent)
随机梯度下降。与经典梯度下降几乎相同,但我们每次仅利用一个样本数据来估计下一个可能的$w_{t+1}$,也就是 $$ w_{t+1} = w_t +\eta\cdot y_jx_j $$ $j$为我们在$M$中随机挑选的一个样本。
MBGD(Mini-Batch Gradient Descent)和BGD(Batch Gradient Descent)
小批量梯度下降和批量梯度下降。小批量即选取一部分样本进行梯度下降计算。这种方法较为常用。我们利用这种方法可以极大地减少计算量。
Advantages and Disadvantages
在数据集线性可分时,感知器虽然可以找到一个超平面把两类数据分开, 但并不能保证能其泛化能力。
感知器对样本顺序比较敏感。每次迭代的顺序不一致时,找到的分割超平面也往往不一致。
如果训练集不是线性可分的,就永远不会收敛[Freund and Schapire, 1999]。
多层人工神经网络
多层人工神经网络也就是多层感知器组成。也就是一般我们除了输入层输出层以外,还有隐藏层。
ANN
ANN是多层前馈人工神经网络。前馈我们一般叫feed-forward。在递归(Recurrent)神经网络中,允许同一层结点相连或一层的结点连到前面各层中的结点。
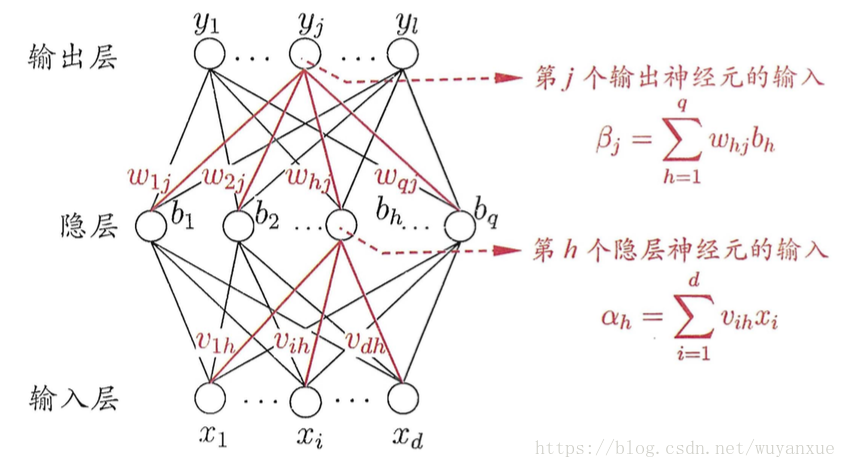
激活函数
我们有许多激活函数与激活函数的变种。
Sigmoid

Sign
$$ \mbox{Sign}(x) = \begin{cases} -1, &x0\\ \end{cases} $$
Sigmoid
$$ \mbox{Sigmoid}(x) = \frac{1}{1+e^{-x}} $$
左端趋近于0,右端趋近于1,且两端都趋于饱和.
关于函数饱和解释:参考https://www.cnblogs.com/tangjicheng/p/9323389.html

如果我们初始化神经网络的权值为 [0,1] 之间的随机值,由反向传播算法的数学推导可知,梯度从后向前传播时,每传递一层梯度值都会减小为原来的0.25倍,如果神经网络隐层特别多,那么梯度在穿过多层后将变得非常小接近于0,即出现梯度消失现象;当网络权值初始化为 (1,+∞) (1,+∞)(1,+∞) 区间内的值,则会出现梯度爆炸情况。 数学分析见文章:https://www.jianshu.com/p/917f71b06499
Sigmoid 的 output 不是0均值(即zero-centered)。这会导致后一层的神经元将得到上一层输出的非0均值的信号作为输入。 其解析式中含有幂运算,计算机求解时相对来讲比较耗时。对于规模比较大的深度网络,这会较大地增加训练时间.
Tanh
$$ \mbox{tanh}(x) = \frac{2}{1+e^{-2x}}-1 = \frac{e^x-e^{-x}}{e^x+e^{-x}} $$
它解决了Sigmoid函数的不是zero-centered输出问题,然而,梯度消失(gradient vanishing)的问题和幂运算的问题仍然存在。
ReLu
$$ \mbox{ReLu}(x) = \max(x,0) $$

是个分段线性函数,显然其导数在正半轴为1,负半轴为0,这样它在整个实数域上有一半的空间是不饱和的。相比之下,sigmoid函数几乎全部区域都是饱和的.
ReLU虽然简单,但却是近几年的重要成果,有以下几大优点:
1) 解决了gradient vanishing问题 (在正区间)
2)计算速度非常快,只需要判断输入是否大于0
3)收敛速度远快于sigmoid和tanh
ReLu是分段线性函数,它的非线性性很弱,因此网络一般要做得很深。但这正好迎合了我们的需求,因为在同样效果的前提下,往往深度比宽度更重要,更深的模型泛化能力更好。所以自从有了Relu激活函数,各种很深的模型都被提出来了,一个标志性的事件是应该是VGG模型和它在ImageNet上取得的成功.
ReLU也有几个需要特别注意的问题:
1)ReLU的输出不是zero-centered
2)某些神经元可能永远不会被激活(Dead ReLU Problem),导致相应的参数永远不能被更新。有两个主要原因可能导致这种情况产生: (1) 非常不幸的参数初始化,这种情况比较少见 (2) learning rate太高导致在训练过程中参数更新太大,不幸使网络进入这种状态。解决方法是可以采用Xavier初始化方法,以及避免将learning rate设置太大或使用adagrad等自动调节learning rate的算法。
尽管存在这两个问题,ReLU目前仍是最常用的activation function,在搭建人工神经网络的时候推荐优先尝试!
Swish函数(Google大脑团队)
$$
\mbox{Swish}(x) = x\cdot \mbox{Sigmoid}(x)
$$
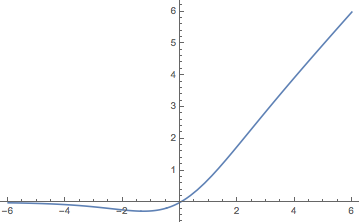
从图像上来看,Swish函数跟ReLu差不多,唯一区别较大的是接近于0的负半轴区域, Google大脑做了很多实验,结果都表明Swish优于ReLu
Gated linear units(GLU)激活函数(facebook提出)
https://blog.csdn.net/qq_32458499/article/details/81513720
Leaky ReLU函数(PReLU)
函数表达式
$$
f(x) = \max(\alpha x,x)
$$

人们为了解决Dead ReLU Problem,提出了将ReLU的前半段设为$\alpha x$而非0,通常$\alpha=0.01$。另外一种直观的想法是基于参数的方法,即Parametric ReLU:$f(x)=\max(\alpha x,x)$,其中$\alpha$可由反向传播算法学出来。理论上来讲,Leaky ReLU有ReLU的所有优点,外加不会有Dead ReLU问题,但是在实际操作当中,并没有完全证明Leaky ReLU总是好于ReLU。
ELU (Exponential Linear Units) 函数
$$
f(x) = \begin{cases}
x,\quad &\mbox{if }x>0\
\alpha(e^x-1),&\mbox{otherwise}
\end{cases}
$$

ELU也是为解决ReLU存在的问题而提出,显然,ELU有ReLU的基本所有优点,以及:
- 不会有Dead ReLU问题
- 输出的均值接近0,zero-centered
它的一个小问题在于计算量稍大。类似于Leaky ReLU,理论上虽然好于ReLU,但在实际使用中目前并没有好的证据ELU总是优于ReLU。
MaxOut函数
论文《maxout networks》
Maxout是深度学习网络中的一层网络,就像池化层、卷积层一样等,我们可以把maxout 看成是网络的激活函数层。如果我们输入特征向量为:$X = (x_1,x_2,\ldots,x_d)$,也就是输入$d$个神经元。Maxout对于每个隐藏神经元计算如下:
$$
h_i(x) = \max_{j\in[1,k]}z_{ij}
$$
神经网络激活函数汇总(Sigmoid、tanh、ReLU、LeakyReLU、pReLU、ELU、maxout)
应用中如何选择合适的激活函数?
这个问题目前没有确定的方法,凭一些经验吧。
1)深度学习往往需要大量时间来处理大量数据,模型的收敛速度是尤为重要的。所以,总体上来讲,训练深度学习网络尽量使用zero-centered数据 (可以经过数据预处理实现) 和zero-centered输出。所以要尽量选择输出具有zero-centered特点的激活函数以加快模型的收敛速度。
2)如果使用 ReLU,那么一定要小心设置 learning rate,而且要注意不要让网络出现很多 “dead” 神经元,如果这个问题不好解决,那么可以试试 Leaky ReLU、PReLU 或者 Maxout.
3)最好不要用 sigmoid,你可以试试 tanh,不过可以预期它的效果会比不上 ReLU 和 Maxout.